

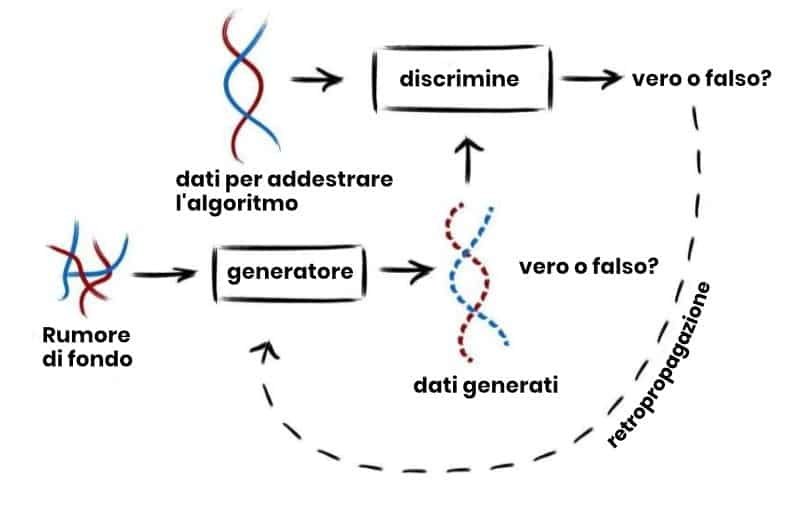
Entre los nuevos algoritmos y los avances de TI, las máquinas ahora pueden aprender modelos cada vez más complejos. Llegan a generar datos sintéticos de alta calidad, como imágenes fotorrealistas, e incluso hojas de vida de humanos ficticios.
ahora un estudio publicado en la revista internacional PLoS Genetics muestra el uso avanzado del aprendizaje automático en datos biométricos. A partir de biobancos existentes, el sistema genera bloques enteros de genoma humano que no pertenecen a humanos reales pero que tienen las características de un genoma real.
Pasando por alto el problema de la privacidad
“Las bases de datos genómicas existentes son un recurso invaluable para investigación biomédica," Él dice Burak Yelmen, primer autor del estudio e investigador junior de genética de poblaciones modernas en la Universidad de Tartu. “El problema es que no son de acceso público ni están protegidos por procedimientos de aplicación prolongados y exhaustivos debido a preocupaciones éticas válidas. Esto crea una barrera científica importante para los investigadores. Un genoma generado por una máquina, un "genoma artificial", puede ayudarnos a superar el problema dentro de un marco ético seguro ".
:format(jpg):extract_cover()/https%3A%2F%2Fscx1.b-cdn.net%2Fcsz%2Fnews%2F800a%2F2021%2F13-machinelearn.jpg)
El equipo multidisciplinar realizó más análisis para evaluar la calidad del genoma generado por el aprendizaje automático en comparación con el real. "Sorprendentemente, este genoma imita las complejidades que podemos observar dentro de las poblaciones humanas reales y, para la mayoría de las propiedades, son indistinguibles de los otros genomas del biobanco utilizado para entrenar nuestro algoritmo. Salvo un detalle: no pertenecen a ningún donante de genes ”, dijo el Dr. Luca Pagani, uno de los autores principales del estudio y compañero de Mobilitas Pluss.
Un genoma generado por una máquina, un "genoma artificial", puede ayudarnos a superar el problema dentro de un marco ético seguro.
Burak Yelmen
¿Es realmente un genoma original o una copia "escupida"?
El estudio también incluye la evaluación de la proximidad del genoma artificial al genoma real para verificar si se conserva la privacidad de las muestras originales. “Si bien detectar fugas de privacidad en miles de genomas puede parecer una búsqueda de una aguja en un pajar, la combinación de múltiples medidas estadísticas nos permite monitorear de cerca todos los modelos. Curiosamente, la exploración detallada de patrones de dispersión complejos conduce a su vez a otras mejoras en la evaluación de GAN y alimentará el campo del aprendizaje automático ”. Decir que es el Dr. jay flora, coordinador de estudios e investigador del CNRS, Centro Nacional Francés de Investigaciones Científicas).
Con todo, los enfoques de aprendizaje automático ya proporcionados caras, biografías y muchas otras características a un puñado de seres humanos imaginarios. Ahora también sabemos más sobre su biología. Estos humanos ficticios con genomas realistas podrían servir como banco experimental en lugar de genomas reales que no están disponibles públicamente.

