

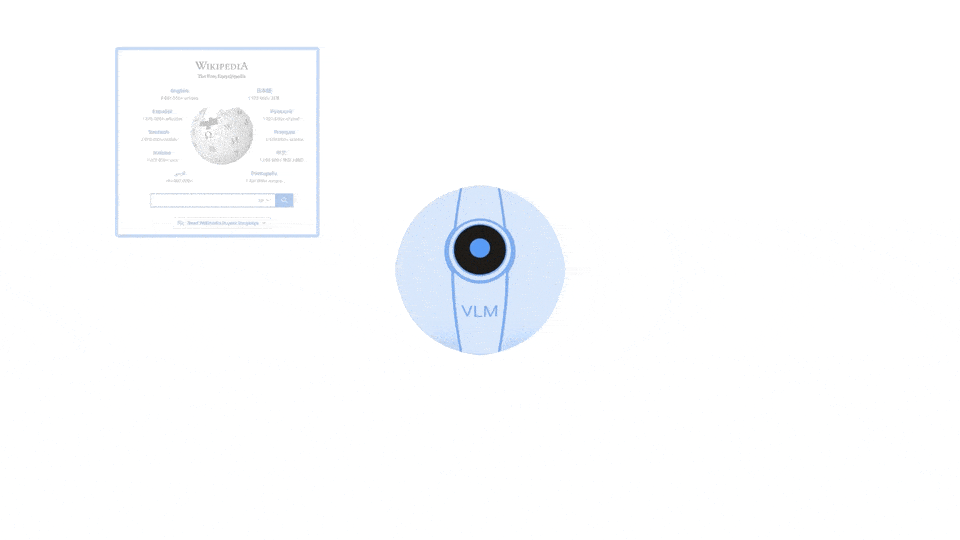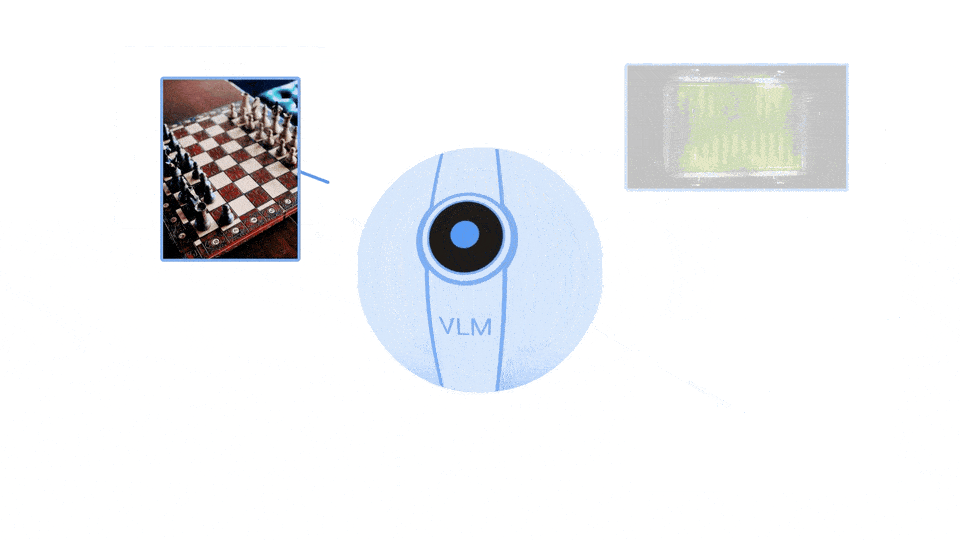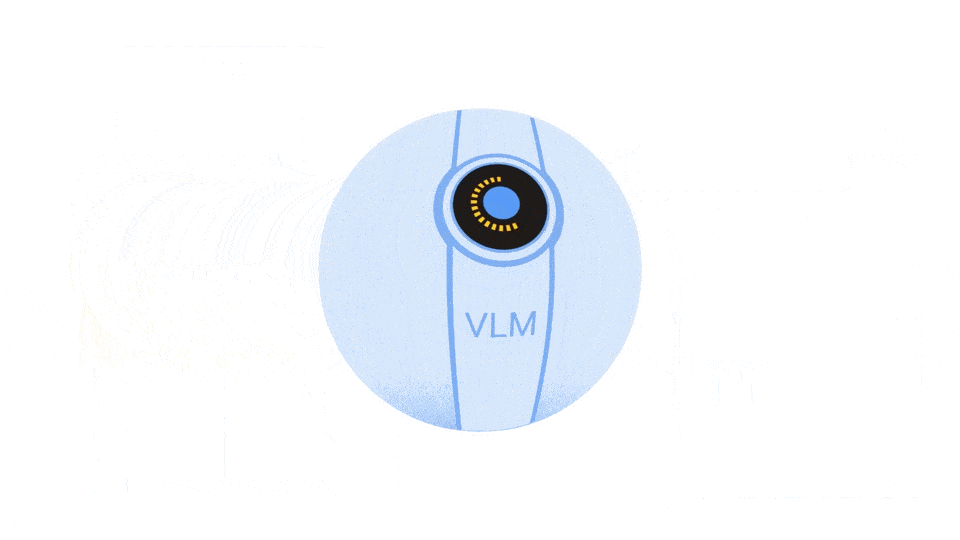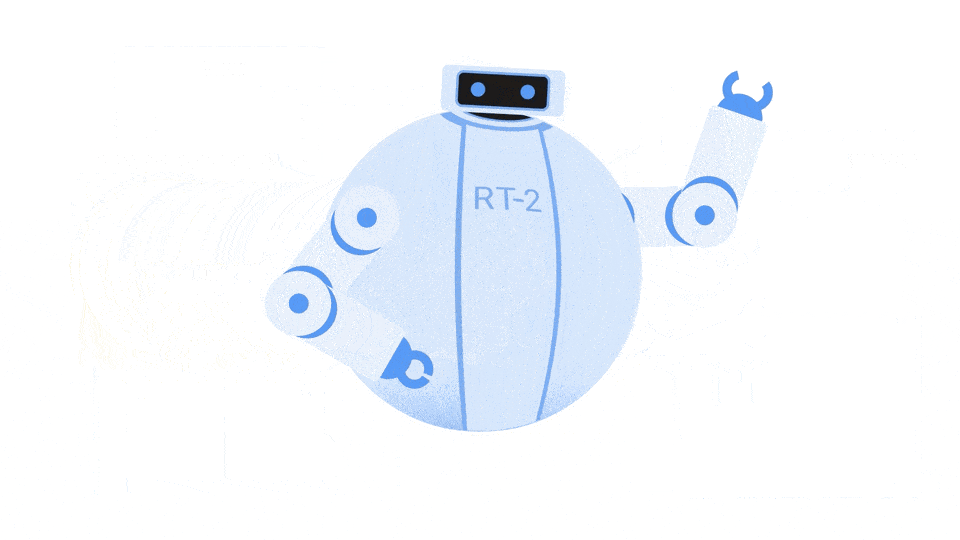
En un ambiente luminoso, repleto de monitores y equipamiento tecnológico, un robot se alza como protagonista. Su estructura metálica refleja la luz, pero es en sus "ojos" donde se esconde la verdadera magia. Estos ojos, impulsados por el modelo RT-2 de DeepMind, son capaces de ver, interpretar y actuar.
Mientras el robot se mueve con gracia, los científicos que lo rodean examinan cada uno de sus movimientos. No es sólo una pieza de metal y un circuito, sino la encarnación de una inteligencia que une el vasto mundo de la web con la realidad tangible.

La evolución del RT-2
La robótica ha recorrido un largo camino en los últimos años, pero Mente profunda simplemente llevó el juego a un nivel completamente nuevo. Ilustrado en un papel recién estrenado llega RT-2. ¿Cosas? Se trata de un modelo visión-lenguaje-acción (VLA) que no sólo aprende de datos web, sino también de datos robóticos, traduciendo este conocimiento en instrucciones generalizadas para el control robótico.
En una era donde la tecnología avanza a pasos agigantados, el RT-2 representa un salto significativo, prometiendo revolucionar no sólo el campo de la robótica, sino también la forma en que vivimos y trabajamos todos los días. Pero ¿qué significa esto en la práctica?
DeepMind RT-2, de la visión a la acción
Los modelos de lenguaje de visión de alta capacidad (VLM) están entrenados en grandes conjuntos de datos, y esto también los hace extraordinariamente buenos para reconocer patrones visuales o lingüísticos (operando, por ejemplo, en diferentes idiomas). Pero imagina poder hacer que los robots hagan lo que hacen estos modelos. De hecho, deja de imaginarlo: DeepMind lo está haciendo posible con RT-2.
Transformadores robóticos 1 (RT-1) fue una maravilla por derecho propio, pero RT-2 va más allá, mostrando capacidades de generalización mejoradas y una comprensión semántica y visual que va más allá de los datos robóticos a los que ha estado expuesto.
Razonamiento en cadena
Uno de los aspectos más fascinantes de RT-2 es su capacidad de razonamiento en cadena. Puede decidir qué objeto podría usarse como un martillo improvisado o qué tipo de bebida es mejor para una persona cansada. Esta capacidad de razonamiento profundo podría revolucionar la forma en que interactuamos con los robots.
Y lo peor de todo es que aún podrías pedirle a un robot que te prepare un buen café para recuperar algo de claridad.
Pero, ¿cómo controla DeepMind RT-2 un robot?
La respuesta está en cómo fue entrenado. De hecho, utiliza una representación similar a los tokens de idioma que explotan plantillas como ChatGPT.
RT-2 demostró asombrosas capacidades emergentes, como la comprensión de símbolos, el razonamiento y el reconocimiento humano. Habilidades que actualmente muestran una mejora de más de 3x en comparación con modelos anteriores.
Con RT-2, Mente profunda no solo mostró que los modelos de visión-lenguaje pueden transformarse en poderosos modelos de visión-lenguaje-acción, sino que también abrió la puerta a un futuro en el que los robots pueden razonar, resolver problemas e interpretar información para realizar una amplia gama de tareas en el mundo real. mundo.

¿E ora?
En un mundo donde la inteligencia artificial y la robótica serán cada vez más centrales, RT-2 nos muestra que la próxima evolución no será puramente técnica, sino "perceptual". Las máquinas comprenderán y responderán a nuestras necesidades de formas que nunca imaginamos.
Si esto es sólo el comienzo, quién sabe lo que deparará el futuro.

